Wednesday, April 10, 2019
What I've Done
So I've been busy over the past year and wanted to share a bit about what I am presenting at SOURCE Boston 2019. I'm actually giving two talks this year;
1. Let's Blow Up the SIEM and Start Over (Wednesday, 2:20 PM)
2. Cloud Intrusion Detection and Threat Hunting With Open Source Tools (Friday, 1:00 PM )
The second is actually a sequel to my 2017 talk, "Engineering Challenges Doing Intrusion Detection in the Cloud" where I shared the results of a large research spike in 2015-2017. In 2018, I continued this work and developed a framework for doing behavioral intrusion detection and threat hunting using FOSS (free and open source) tools. This became the "SpaceCake" project you may have seen me talk about at the meetups and BSides events. In this talk I will present this framework and share some real-world data examples (and as before, there is a threat hunting exercise using real data.) Conventional wisdom sometimes holds that this is too much detail for a conference talk but attendees consistently tell me they love seeing real threat data so I keep including it.
The first talk is partly about how, once upon a time, my business stakeholders were suffering from what I call "inflation fatigue" as we faced a roughly $4 million annual spend on tools combined with an increasing cost curve for security staff due to historic levels of full employment and market demand. At the same time, neither security nor operations teams were very happy with the expensive security tools we were using because of what I called "product sprawl." One day, my leadership asked if we could throw it out and start over with free and open source (F/OSS) tooling. I later spent 2018 developing the SpaceCake project to do that after I noticed several different organizations were asking me for the same thing.
SpaceCake used data and telemetry from a wide variety of open source tools and instrumentation to accomplish all nine of Anton Chuvakin's SIEM use cases including cloud activity monitoring; EDR (endpoint detection and response; intrusion detection; malware detection; network monitoring and threat intelligence. Interestingly, we can also do machine learning based anomaly detection using the significant terms aggregation in ELK and I will show examples of how I use this to detect threats and intrusions that are hard to find using conventional or specification based rules.
Friday, January 04, 2019
Living Without SOCs

A traditional SOC is a dedicated space that tried to look like the military command center in the movie "WarGames" - big screens on the wall with data displays that try to visualize threats and security things, flashing and blinking lights, and serious looking analysts staring at two or more monitors filled with alerts and things. When an important alert arrives, the analysts turn on the flashing red light and start an "incident" which often means herding people into a meeting or conference call where people are asked to gather information or take action. The conference call / meeting approach is partly for communication, partly for coordination, and partly a means of getting things done.
This can be very inefficient. Senior engineers typically don't want to be "goldfish" on display in a SOC reading alerts all day and junior engineers don't have the experience or knowledge to investigate and root cause incidents - hence the conference calls, which are a means to obtain assistance from more senior operations or engineering people. At the same time, the cost of having two different operational teams, in a 24/7 world, can be astronomical.
Another approach is to empower operations teams to handle security incidents themselves by investing in security resources there. What does that mean? I would start by identifying a leader. For an operations team new to security, where no one is the heir apparent, I would hire someone to be a security lead who can mentor the team and help them learn to work security issues. In my experience, security leads are self-selecting through some innate instincts and are not waiting for someone to start their training or prompt them to do so. I have not had super-great results trying to train someone to be a security lead who has shown no previous interest in the subject and I don't think this is a productive approach. In some cases, there are one or more team members who are already on the way to being self-taught in security and we need only encourage this by supporting learning and enrichment activities.
People learn about security in different ways and I believe it is best to allow people to choose their own path. Some people learn by going to conferences and / or taking structured classroom training. Some like to learn by participating in hackathons and capture-the-flag events. Some like to read books or take self-paced training and implementing new found knowledge as they go. For me, as with many people, it has been a combination of all of these things, so having the flexibility to let people identify what kinds of education and enrichment activities they need is key. Funding and supporting such activities is key - a security team needs access to continuous learning to be successful and if your culture cannot support meaningful learning and enrichment activities, security team performance will suffer.
When an existing dev/ops team becomes empowered to investigate and root cause security issues, there are numerous benefits. Velocity is increased and the conference calls can be replaced with asynchronous chats which, in addition to being less harmful to productivity, and facilitating collaboration and information sharing, enhance the team's ability to learn by providing a written record of solutions to issues that can become a knowledge base.
So no, I don't think we must have a traditional SOC - at the end of the day the metrics that matter are MTTK (mean time to know) and MTTR (mean time to resolution) and a virtual SOC can achieve higher velocity on these.
Monday, April 24, 2017
Breathtaking Artwork, Bots Made of Perl and IDS in the Cloud: Why You Should See My Talk at SOURCE 2017

1. This is not a product pitch; this is a talk by and for practitioners. This is "pure" research and retrospective; no security product vendors had control or direction over the research it is based upon. No security product marketing marketing managers had editorial control over the content of the talk (the only downside is that you will be subjected to my breathtaking PowerPoint and art skillz.)
2. The rich data and real-world examples more than make up for any shortcomings in the artwork. We will see several varieties of exploit detonations captured by syscall events; we will examine some perl-based bots taken from real payloads and we will take a look at at the Romanian botnet they connect to.
3. Hunting in the Cloud. We will examine, and analyze, threat and attack detection examples from real-world public cloud environments while considering which kinds of threats, in the cloud, an IDS can and cannot see.
4. Real-world experience that can be taken away and put to use. We will review several years' experience doing intrusion detection in AWS and discuss the pros and cons of various design patterns in great detail.
This is the full abstract:
Title: Engineering Challenges Doing Intrusion Detection in the Cloud
Conventional, specification-based intrusion detection paradigms, particularly around network intrusion detection, are not easily applied to the software defined network abstractions that power multi-tenant public clouds. While there are challenges, there are also opportunities to do a reboot on traditional network security monitoring and embrace new tactics. This talk contains the lessons learned during extensive research and implementation of various forms of intrusion detection and security monitoring in EC2 and AWS. The talk contains extensive data including comparative test results of IDS tools; examination of what works well and what does not; and a fun interactive portion on real-world cloud threat hunting with syscalls.
The general conclusion is that the difficulty associated with doing conventional network intrusion detection in the public clouds is an opportunity in disguise; an opportunity to experiment and reboot IDS to consider alternatives like behavioral detection including alternate data types like syscalls. When intrusion detection was postulated by Denning et. al. thirty years ago it was never intended to be limited to be limited to doing specification based pattern matching on network packet capture streams. In other words, the idea that we -must- have a network IDS simply because we've been doing network IDS for thirty years is sort of tautological.
Tuesday, February 28, 2017
Why We Can't Have Nice Things: The Great SSH Security Debate

On the standard vs. non-standard port debate
First, while I agree that running SSH on a non-standard port is an example of "security by obscurity," this has some tactical advantages. Before you read further, I suggest you try this experiment:
1. Spin up two Linux instances, in a public cloud running SSH; one using keys, and one using passwords.
1a. Start two SSH listeners, one using the standard port 22 and one using a random port not included in any default portscan list (e.g. a default nmap scan.)
1b. Make the SSH ports generally accessible.
2. Instrument each instance with an intrusion detection tool capable of detecting brute force attempts. One (free) option is the OSSEC LIDS (log based intrusion detection) agent. Additional intrusion detection tools are available in the marketplaces.
3. Count the size of the message data structures, and number of associated alerts, each instance generates per day due to brute force activity on port 22 vs. the pseudorandom port.
4. Extrapolate this to a medium or large sized fleet of, say, ten or twenty thousand instances.
In the public clouds, brute force alerts, like many alerts produced by many forms of automated reconnaissance and attempted intrusion campaigns, are supernumerary. In a medium sized fleet, you can easily generate more than one hundred thousand such alerts per day. Assuming you collect and retain security alerts and associated log data for, say, three to six months, we are now burning money (in the form of compute and storage) processing brute force alerts. We're also creating alert fatigue and distracting security analyst / hunters who could be working on something more productive like hunting structured threats. I would argue that running SSH on a non-standard port, in order to manage alert fatigue, is a useful tactic.
Where resources permit, I would actually suggest running three SSH services:
1) A functional service on a nonstandard port which accepts root logins;
2) A functional service on a nonstandard port which accepts non-root logins, if use cases for this exist;
3) A decoy, non-functional service on port 22 that accepts no logins and has no shell.
With this combination, you can adjust your analytics to lower the priority of campaigns against port 22 by unstructured threats that may never realize they're not interrogating a working service. At the same time, alerts involving campaigns against the working services can be raised in priority as these tend to suggest a more determined human attacker who has taken the trouble to find the real SSH services. These are more interesting things to hunt, and time better spent.
On the Bastion Host Design Pattern
Few of us would argue that placing a Bastion in front of a production SSH service is not a useful tactic. Placing a bastion inline, like a firewall, feels safer and this makes everyone feel good. Where this goes wrong, too often, is in at least a couple of ways I can cite:
1. Assumptions may be made that the presence of the bastion has created sort of impenetrable condition that allows security to be relaxed in the environment behind the bastion. A bastion host is not a perfect defense, more than any other technology, and security needs to be applied systemically using the assumption that any single point, including a bastion, may fail at some time.
2. Ineffective or incoherent identity management and logging on SSH sessions or tunnels crossing the bastion. Figuring out exactly who did what - disambiguating user identity and / or context - too often proves to be infeasable in reality due to inadequate logging or user identity management across bastions.
Given a choice between a bastioned environment with weak logging where I cannot establish user context, and a non-bastioned environment with strong identity management and logging, where I an establish user identity, I'd actually tend to choose the latter. Given a choice, I think using a 2FA VPN with hardware tokens, as some are increasingly doing, with very strong identity management and logging, is often preferable to a simple bastion.
On SSH network security in the public cloud
Applying network access controls to SSH is a fine idea in principle that sometimes breaks down due to account sprawl. Organizations love to create lots of accounts in order to create safeguards against different product or application teams stepping on each other's work. Keeping a large and dynamic list of accounts connected to a "bastion" SSH VPC - via peering or VPN - can be harder than it sounds. Security groups don't cross accounts and there is no obvious way to manage security groups or network ACLS across the AWS account boundary. I sometimes wish that we could use account ID as a parameter in security groups in order to allow instances from any account, in the same billing entity organization, to reach certain network services. I've actually suggested this in the past but this its not a simple feature request.
Tuesday, January 03, 2017
There's More Than Five Tuples: Network Security Monitoring With Syscalls
In modern cloud environments like AWS, we have a few options for doing network security monitoring and anomaly detection. We could use native OS-level firewall logs; we could layer on an instance based firewall product; or we could gather flow logs as long as our instances are running in a VPC. The disadvantage of all these approaches is that they are so-called "5-tuple" data types - limited to source and destination IP addresses, ports, and protocols. This is evident when we examine VPC flow logs which are similar to netflow:

Syscall data is superior as it is a 15-tuple data type with much richer data including key contextual parameters in addition to the traditional five tuples:
- The name and path of the process connected to the socket (e.g. which program or service engaged in the network activity)
- The commands and / or arguments associated with the process (e.g. what was the program trying to do)
- The user and group associated with the process (e.g. who did it)
- The PID and PPID of the process
With conventional flow or firewall logs, this kind of contextual detail often requires manual live response which is inherently unscalable due to its labor-intensive nature. Even where we have hunting teams available to do live response and chase down anomalous network activity, intermittent network activity tends to resist root causing unless an analyst happens to be doing live response when the activity manifests. Malware frameworks have long used intermittent and irregular command-and-control beaconing, for this reason, in order to resist detection and prolong persistence. In the cloud, we have another problem: servers may or may not live long enough for an analyst to perform live response. In semi- or hyper-ephemeral environments where instances are frequently created and destroyed, there may be simply be no instance to perform live response on by the time an alert rises to the top of the analysis queue, making effective threat hunting ineffective. In other cases, an instance may have been terminated by a developer or technician who thought this was the best course of action. In some environments, while servers persist long enough for live response, live response is infeasible when SSH or other command shells are unavailable due to philosophical design decisions that SSH or command shell accessibility is an anti-pattern.
The answer to all of this is to instrument in advance and gathering syscall data is the best way I've found in six years to do network security monitoring in the cloud. The Threat Stack technology is possibly the best way to gather and process syscall data at scale.. I've been doing active development in the tool for a while now and have arrived at a set of twenty rules that can detect any kind of network anomaly and produce actionable alerts. They're much more useful to most kinds of network alerts based on flow logs or firewall logs because I can do network behavior anomaly detection (NBAD) in fifteen dimensions instead of five. For example, consider these syscall logs on activity from an nmap scanner:
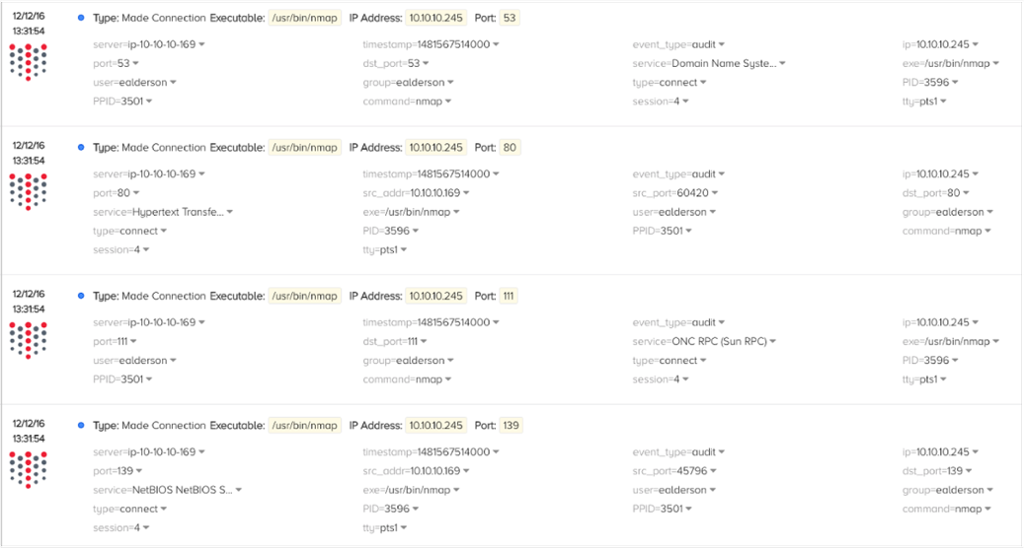
You can see all 15 tuples in the events which allow us to root cause this network behavior as an nmap scan in a matter of seconds without the need to get on the instance and perform live response in order to try and identify the process connected to the sockets, the user who invoked the process, the commands that were executed, and so on.
Using syscall data on file events, one can also perform complex and subtle anomaly detection on file and process events and I plan to explore this next. Example use cases include sensitive file access by shells or editors; file access by data exfil vectors like scp or ftp; and anomalous file access in general. Anomalous file access is another promising method for doing behavioral detection of exploit attempts; for example, a random process, like a Dirty Cow exploit, writing to /etc/passwd, or a non-mySQL process writing to a mySQL configuration file.
Spacefolding Redux: Increasing Hunting Velocity and Mean-Time-To-Know (MTTK)
(Originally written for the Threat Stack blog)
In our last post, we took a look at traditional security incident response vs. the possibility to dramatically increase security velocity (which I affectionately nicknamed “spacefolding”).
We viewed this through the lens of a conventional response timeline that can take hours and days — versus seeing into exactly what occurred and decreasing the Mean Time-To-Know (MTTK) for a security incident -- because all of the relevant information is visible and available to you.
In this post, we’ll take this premise into a real-world example that may be familiar to many organizations running instances on AWS.Consider a routine scanning abuse complaint as an example investigation. When an EC2 instance is observed to be scanning another server, AWS security will issue an abuse report to the instance owner — a sort of admonishment that your instance has been naughty and its behavior must be dealt with.
These reports are typically very terse and may include few details other than the destination port count was exactly one thousand...One thousand ports is exactly the number targeted by a default nmap (the network mapper) scan, and we can surmise that an unauthorized nmap scan is the likely explanation. How do we ascertain this? We need to ask and answer several questions:
- What? Was the cause of the activity indeed a scanner like nmap or was it a misbehaving application? The former is a case for security; the latter a case for the application owner.
- Who? If it was a scanner, which user ran the scan? Who did it?
- Why? Why did a user run a scanner? Was it really them or did someone else login as them using their password?
Answering these questions, in most organizations, takes lots of time and effort.
First, we have to locate the offending EC2 instance and identify whose EC2 account it is running in.
Next, we have to identify the instance and / or application owner and ask them if they can explain this behavior. If the answer is No, as it probably is, we have to obtain keys to the instance in order to login and investigate ourselves. By this time, the running state we could use to solve this mystery has expired and is no longer present for us to observe — the scanner has stopped, its network connections have expired, and the user who did it is no longer logged in.
We set about examining system logs and find nothing of significance because ephemeral events like process execution and network activity do not typically leave traces in system logs because this level of detail would grow the logs until they swamped the file system.
If we’re lucky, there may be some shell command history that we can use to identify which user ran the nmap scanner and scanned the complainant server. If we’re unlucky, we may have to examine authentication logs for the entire day, or more, and question each user one by one until we eventually learn that a user did indeed run the nmap scanner while troubleshooting network connectivity to a remote instance. The user, a support technician, forgot to specify a port parameter and accidentally ran a default nmap scan which covers a thousand common ports, which was flagged by the EC2 security team.
 Figure 1. Syscall events reveal that the network activity came from the nmap scanner.
Figure 1. Syscall events reveal that the network activity came from the nmap scanner. Figure 2. Syscall events identify the original command run by the user who invoked the nmap scanner.
Figure 2. Syscall events identify the original command run by the user who invoked the nmap scanner. Figure 3. Unified authentication events identify where and when the user logged in.
Figure 3. Unified authentication events identify where and when the user logged in.There IS a Better Way
How does using Threat Stack in a routine case like this improve our Mean-Time-To-Know?
With Threat Stack, our team can easily replay system calls at the time of the scan and answer our first two questions above — What? and Who? — using the resulting data. This would allow us to fast forward to step three — Why? — and simply ask the user why she ran this command.
The time savings in even this routine case are significant — minutes instead of hours. This is a velocity increase of a factor of sixty! In more complex cases, I project, the velocity increase may range as high as 200 times. Increased velocity provides blue teams with a tactical advantage; and as blue teams will tell you, they will gladly exploit any tactical advantage they can, because too often the attackers have the advantage. The ability to detect and respond closer to the speed of threats will provide a massive increase in productivity for overloaded security incident response teams.
For more advanced threat hunting teams, a velocity increase provides the ability to disrupt threats, before significant damage is done, instead of simply detecting and responding to losses that have already occurred in the past. This would be the secondary, and probably much larger, benefit of increased velocity.
A Final Word . . .
Spacefolding, for our purposes in this case, refers to a platform like Threat Stack, and the benefit is reducing MTTK. While we are still constrained by the laws of physics and spacetime, we can still significantly impact our response velocity, and potentially disrupt attackers using a purpose-built platform.
Tuesday, November 01, 2016
Increasing Security Velocity With "Spacefolding"
(Originally written for the Threat Stack blog)
I recently added a Starz subscription to my Amazon Prime and found a new supply of science fiction movies. One of these, Deja Vu, is a time travel story from a decade ago; a weird mashup of the post-9/11 terror attack genre mixed with science fiction. In the film, a terror attack takes place in New Orleans and a small army of government men-in-black from various state and Federal agencies respond. Because the attack involved a ferry, the NTSB and FBI collaborate along with elements of the ATF, including a talented investigator played by Denzel Washington.
I recently added a Starz subscription to my Amazon Prime and found a new supply of science fiction movies. One of these, Deja Vu, is a time travel story from a decade ago; a weird mashup of the post-9/11 terror attack genre mixed with science fiction. In the film, a terror attack takes place in New Orleans and a small army of government men-in-black from various state and Federal agencies respond. Because the attack involved a ferry, the NTSB and FBI collaborate along with elements of the ATF, including a talented investigator played by Denzel Washington.
While the FBI / NTSB task force sets about the painstaking work of accident reconstruction and crime
 scene forensics, Denzel’s character is recruited by a sort of super-secret element of DHS using an experimental technology called “spacefolding” to directly observe the past. The “spacefolding” machine displays a single point in space exactly 48 hours in the (relative) past. The DHS time scientists recruit Denzel’s character because they realize they need an investigator to know where to look, in order to be looking in the right place during the prelude to the attack, and solve the case by witnessing the perpetrators in action.
scene forensics, Denzel’s character is recruited by a sort of super-secret element of DHS using an experimental technology called “spacefolding” to directly observe the past. The “spacefolding” machine displays a single point in space exactly 48 hours in the (relative) past. The DHS time scientists recruit Denzel’s character because they realize they need an investigator to know where to look, in order to be looking in the right place during the prelude to the attack, and solve the case by witnessing the perpetrators in action.
OK, you’re saying, I’m due back on Earth now. All of this is fun science fiction and vaguely entertaining, but what does it have to do with anything, let alone security velocity?
scene forensics, Denzel’s character is recruited by a sort of super-secret element of DHS using an experimental technology called “spacefolding” to directly observe the past. The “spacefolding” machine displays a single point in space exactly 48 hours in the (relative) past. The DHS time scientists recruit Denzel’s character because they realize they need an investigator to know where to look, in order to be looking in the right place during the prelude to the attack, and solve the case by witnessing the perpetrators in action.OK, you’re saying, I’m due back on Earth now. All of this is fun science fiction and vaguely entertaining, but what does it have to do with anything, let alone security velocity?
Well, back, in the real world, we cannot fold space and observe the past — but what if we could?


We have experienced similar challenges in the realms of security threat hunting, host intrusion detection, and incident response for decades. When investigating IDS and other alerts, security teams often try to partially reconstruct into the past and divine what happened. This examination of a running system is called live response and involves the sifting of logs and artifacts for clues not altogether unlike an accident reconstruction or crime scene forensic technician, albeit less formal in methodology.
Consider the differential time and effort cost of the two approaches in the film:
Security analysts examine current state including things like open ports and sockets, attached processes, file handles, and active user sessions. If current state is unrevealing, because the activity under investigation took place in the past, analysts gather logs and file systems and start creating timelines — another method of attempting to reconstruct the past.
What if we could actually see the past instead of painstakingly reconstructing it? This would give us a massive shortcut to answering questions during live response and routine investigation. My recent work with Threat Stack is as close to Spacefolding as I can imagine getting — using the TTY Timeline, one can actually go back to events that occurred in the past, observe what happened, and get answers in minutes. For a typical security team, this can reduce live response time from hours to minutes (100–200x). Consider the difference between conventional live response and observing past security events by “spacefolding”:
So how could we observe the past? Much of what we know about physics suggests we are stuck in a linear time existence. There may be additional dimensions, including some with possibilities of nonlinear time, but that doesn’t help us here. What we can do is to record state in great detail and play it back using a reference monitor connected to an enormous logging and analytics engine. Imagine using something like auditd to record all system calls or syscalls — command and process activity, file activity, network connections with attached processes, user logins and privilege elevations, and TTY command history. If we record this level of detail into a database that allows us to query and sift the data, we can observe detailed state and past events on a server instance in the past.
In my next post, I will dig deeper into an actual use case of “Spacefolding” with Threat Stack and how it can dramatically increase security velocity.
Read more on the Threat Stack Blog: http://blog.threatstack.com/increasing-security-response-velocity
Sunday, July 12, 2015
Simply Explained: Why Do We Need So Many Security Test Things?

Software is like entropy. It is difficult to grasp, weighs nothing, and obeys the second law of thermodynamics; i.e. it always increases.
- Norman Ralph Augustine
Why is security testing so complicated? Why do we need so many kinds of security tests for web applications including both dynamic analysis (or DAST) and static analysis or (SAST) - in addition to threat modeling, whatever that is?
During the recent controversy on airplane security topics, I finally thought of an analogy to explain why we need so many different kinds of activities in software security lifecycle endeavors. Typically among the first questions asked about software security is something to the effect of, "should we use this vulnerability scanner or that?" The answer, of course, is that you need more than a simple vulnerability scan to test modern web applications.
In the vulnerability management world, things are simpler - scanners interrogate listening ports and test binary services for known vulnerabilities using a catalogue of known flaws. It's a simple test -because- there is a catalogue; the list of vulnerabilities you're looking for has been provided in advance by security researchers and / or vulnerability management vendors.These assumptions break down in the web application space because web applications tend to be unique; they've not been tested or assessed before, so there is no catalogue or list of known flaws to look for. There are generic tests for well-known classes of issues, but these have widely varying effectiveness, and no single test or "scanner" can thoroughly assess any web application running on any framework.
During the recent controversy on airplane security topics, I finally thought of an analogy to explain why we need so many different kinds of activities in software security lifecycle endeavors. Typically among the first questions asked about software security is something to the effect of, "should we use this vulnerability scanner or that?" The answer, of course, is that you need more than a simple vulnerability scan to test modern web applications.
In the vulnerability management world, things are simpler - scanners interrogate listening ports and test binary services for known vulnerabilities using a catalogue of known flaws. It's a simple test -because- there is a catalogue; the list of vulnerabilities you're looking for has been provided in advance by security researchers and / or vulnerability management vendors.These assumptions break down in the web application space because web applications tend to be unique; they've not been tested or assessed before, so there is no catalogue or list of known flaws to look for. There are generic tests for well-known classes of issues, but these have widely varying effectiveness, and no single test or "scanner" can thoroughly assess any web application running on any framework.
An analogy with airplane manufacturing is one way to think about this. If dynamic analysis is analogous to the wind tunnel test for an airplane, think of static analysis as a sort of X-Ray.
In the aviation world, they perform complex X-ray imaging techniques like computed tomography (CT). These kinds of tests are used to find subtle defects in materials or cases where precision tolerances are out of spec. These kinds of defects in materials and workmanship might never be detected in a wind tunnel test because the necessary conditions for failure aren't quite right or the duration isn't long enough (you can't keep the plane in the wind tunnel for years in order to perform a complete simulation of its life cycle). In the software world, we perform static analysis as a sort of "X-ray" to look for subtle flaws and imprecise tolerances in the code that might fail at some point in the future if conditions become just right.
Perhaps better known is the so-called "wind tunnel" test where the aircraft is exposed to in-flight conditions to test performance and find out what it takes to create failure. Airplane engine testing includes putting high velocity water and hail, and even dead birds, into the engine while running to see if the engine can handle unwanted input without failure. This is sort of similar to dynamic software analysis where an running application is exposed to inappropriate input in order to see if it fails or if it recovers and keeps running. Instead of hail and dead birds, during security testing, we feed software various kinds of unexpected or unwanted data and input.
The reason these automated tests are accompanied by manual testing - the so-called "pentesting" - is that the machines can't think and the test designers can't anticipate every possible failure state in every application. In the airplane world, there are only a few things that can reasonably be expected to interfere with a running engine - clouds, rain, hail, fog, birds, lightning, possibly supercooled liquid water, and various atmospheric gases. There just aren't that many kinds of things in the air. In the software world, abuse cases are supernumerary - there are millions and millions of permutations of unwanted data inputs that can be thrown at a running application. While not all make sense to test, and only a handful may actually cause failure, sometimes only a human can figure out just the right input to produce a failure state that is "exploitable" - meaning it creates failure in a way that yields control of the program.
Lastly, the activity known as threat modeling is also sort of poorly understood. Threat modeling is a sort of systematic design review that seeks to uncover design flaws - often design aspects based on assumptions made during the design phase that, while convenient or expedient, prove to be flawed upon closer examination. In other words, something is working as designed, but the design is insecure. An example in the aviation world would be reviewing the design of the onboard networks to see if there are any potential interconnections between control and entertainment systems that could be abused by a malicious passenger under the right conditions. Security design flaws, and their underlying assumptions, cannot usually be found by any automated test, at least not until the machines can think.
The output of threat modeling is often more likely to be design flaws (things that are working as designed, but whose design is insecure) more than security defects (things that are insecure because they fail when exposed to unexpected conditions).
Hopefully this explains why we have so many kinds of test cycles. Each test activity finds things the others cannot, and the only way to thoroughly test and assess product security is to use all three techniques. When the machines can think, and can create their own code, we may have code with security quality indexes that are an order of magnitude higher than we have today. It seems likely that the first thought that will be articulated by the first sentient program, if and when it arrives, will be to critique the quality if the human-written code it was created with.
Subscribe to:
Comments (Atom)