 In the physical world, we could save billions by forgoing firewall budgets and instead relying on host based firewalls for enforcement of access controls. We don't, of course, for several reasons including the notion of mandatory access control - hosts can't easily disable or tamper with physical firewalls in their path. Physical firewall and IDS/IPS devices also provide scalable management and reporting features that are important in the enterprise.
In the physical world, we could save billions by forgoing firewall budgets and instead relying on host based firewalls for enforcement of access controls. We don't, of course, for several reasons including the notion of mandatory access control - hosts can't easily disable or tamper with physical firewalls in their path. Physical firewall and IDS/IPS devices also provide scalable management and reporting features that are important in the enterprise.In the virtual world, there are an increasing number of firewall and intrusion detection / prevention products for VMware environments which utilize the VMsafe APIs. These products provide layer 3 and 4 access controls (ACLs) and intrusion detection / prevention to vNetworks. The vSwitch and dvSwitch are essentially layer two devices (of a different sort; unlike their physical world counterparts, they are not learning switches, as there is no need - the hypervisor already knows everyone's MAC address). Layer three capabilities have long been provided by virtual firewall appliances or by routing different VLAN backed portgroups through pFirewalls. The notion of enforcing security in the virtual machine monitor, or VMM, may date back to a 2002 paper - in which the diagram above appears - available at Stanford. Enforcing access controls in the monitor provides for mandatory access control, unlike host firewalls running in the guests, and has numerous advantages. With ACLs enforced in the monitor, it is no longer critical to consider portgroup placement with respect to virtual firewall appliances or pFirewalls enforcing ACLs between VLAN backed portgroups or worry about associated misconfiguration accidents. Management is simpler without the supermassive firewall rulesets that can be a fixture of pFirewalls attempting to regulate virtual networks. Performance and scalability limitations of virtual firewall appliances becomes moot. Firewall policy is enforced by the monitor and travels with a guest when it changes hosts or portgroups. From the guest OS perspective, it looks like a pFirewall has been attached to its vNIC. Another advantage, of course, is that traffic between guests can be inspected and regulated when no firewall, virtual or physical, sits in their path. Virtual networks can be instrumented, monitored and regulated as thoroughly as in physical networks.
Last year I began wo
 rking with one of the first VMsafe firewall/IDS products from Altor (now Juniper) in order to meet complex security requirements in virtual networks and generally enjoy more enterprise-like security capabilities as we're accustomed to having in the physical world. The Juniper product has a rich policy model and can automatically apply firewall policies based on a guest's name, portgroup, operating system, and so on. Policies can, of course, also be applied to individual VMs or to static or dynamic groups. Numerous external integrations are available; packet data can be fed to a Snort instance, or Juniper IDP device, or to a sniffer like Wireshark or Network Monitor. Syslog event feeds can be directed to log aggregation or security event/information managers. Netflow collection and export is also supported; netflow v9 can be exported to a netflow analysis tool. The management UI has a decent interface for query, retrieval and analysis of firewall and IDS event data for cases where it is necessary to perform network forensics using the firewall manager alone.
rking with one of the first VMsafe firewall/IDS products from Altor (now Juniper) in order to meet complex security requirements in virtual networks and generally enjoy more enterprise-like security capabilities as we're accustomed to having in the physical world. The Juniper product has a rich policy model and can automatically apply firewall policies based on a guest's name, portgroup, operating system, and so on. Policies can, of course, also be applied to individual VMs or to static or dynamic groups. Numerous external integrations are available; packet data can be fed to a Snort instance, or Juniper IDP device, or to a sniffer like Wireshark or Network Monitor. Syslog event feeds can be directed to log aggregation or security event/information managers. Netflow collection and export is also supported; netflow v9 can be exported to a netflow analysis tool. The management UI has a decent interface for query, retrieval and analysis of firewall and IDS event data for cases where it is necessary to perform network forensics using the firewall manager alone.Possibly the most compelling feature, for cloud projects, is an API that allows for automation. The Firewall management server has an authenticated web service API that provides for programmatic access. Virtual machines' firewall policies can be configured and assigned by external orchestration tools and applications, using the API, in order to permit cloud consumers to self-provision virtual machines with pre-assigned firewall policies without waiting for manual intervention by a firewall or network administrator.
The vFirewalls and their policies can fail open or closed; guests with no associated policy can receive a restrictive default policy to prevent fail-open conditions and connectivity can be denied if someone tries to bypass security policy by adding hosts without firewall modules to a cluster as shown in the adjacent screenshot. A "monitor only" mode of operation is available for cases where monitoring without ACL enforcement is required - useful for environments just beginning to develop firewall policies for their virtualized applications.

Deployment consists of instantiating a processing engine and loading a signed kernel module on each host. A central management (virtual) appliance provides the management UI and does the work of policy distribution and event collection from each engine. A new vSwitch/portgroup combination- a vmservice vswitch with a VMkernel porgroup - is created . In the adjacent screenshot you can see the network plumbing for an engine named "22".
{kind=link}
Let's look at some examples and case studies. In the first example, Windows VM 1138 has downloaded a buffer overrun exploit program and used it to obtain a reverse shell with system privileges on neighboring Windows VM 1142. The upper command window is running a netcat listener to receive the incoming shell:
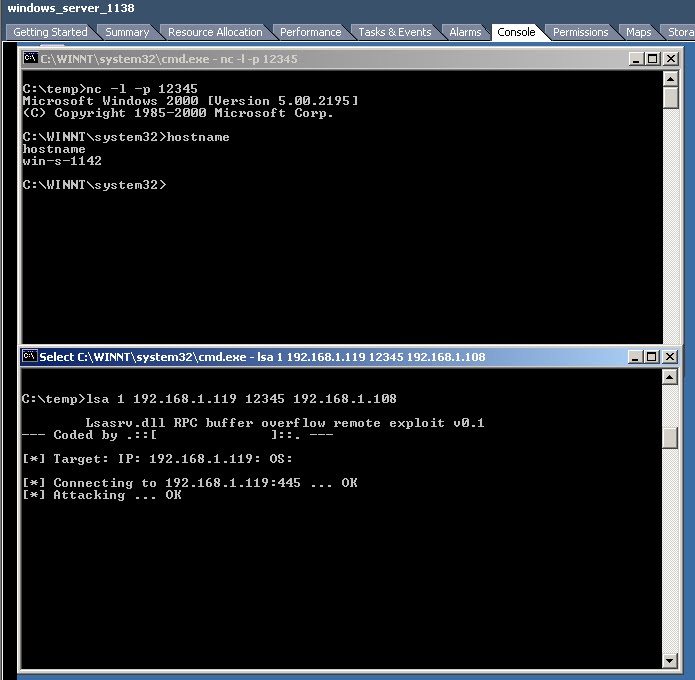 The vIDS detects and alerts on the PE binary download in a web session as well as the actual exploit being fired; all of this is visible in the summary vIDS data below. While the download might be seen by a pIDS, the exploit traffic could only have been seen by the vIDS:
The vIDS detects and alerts on the PE binary download in a web session as well as the actual exploit being fired; all of this is visible in the summary vIDS data below. While the download might be seen by a pIDS, the exploit traffic could only have been seen by the vIDS: There is no particular reason these Windows servers need to talk to one another's DCE,RPC or SMB ports so we can easily apply firewall rules that block these ports between them. Here are some firewall block events, form the vFirewall, after this policy has been implemented:
There is no particular reason these Windows servers need to talk to one another's DCE,RPC or SMB ports so we can easily apply firewall rules that block these ports between them. Here are some firewall block events, form the vFirewall, after this policy has been implemented: With this policy in place, Windows VM 1138 can no longer fire exploits at these ports on its neighboring Windows VMs so the exploit fails to connect to the target, blocked by the new vFirewall policy:
With this policy in place, Windows VM 1138 can no longer fire exploits at these ports on its neighboring Windows VMs so the exploit fails to connect to the target, blocked by the new vFirewall policy: In the next example, a Linux guest has opened a reverse shell backdoor on a neighboring VM infected with the enye rootkit (I wrote about this case study in great detail a previous post). In this case the vIDS produced a generic ICMP detect which is a useful anomaly detection method; in this case ICMP is not commonly used by these web servers (and ICMP between unrelated VMs would, of course, be unusual and suspicious):
In the next example, a Linux guest has opened a reverse shell backdoor on a neighboring VM infected with the enye rootkit (I wrote about this case study in great detail a previous post). In this case the vIDS produced a generic ICMP detect which is a useful anomaly detection method; in this case ICMP is not commonly used by these web servers (and ICMP between unrelated VMs would, of course, be unusual and suspicious): The ICMP exchange is actually a technique used by enye to authenticate a request for a rootshell. The ICMP packets contain the string "ENYELKMICMPKEY" as can be seen below in a tcpdump capture viewed in wireshark. We could easily create a signature for this ICMP traffic (and its operators could easily change it to look more like normal ICMP, which is why behavioral anomaly detection is often useful in combination with specification based intrusion detection):
The ICMP exchange is actually a technique used by enye to authenticate a request for a rootshell. The ICMP packets contain the string "ENYELKMICMPKEY" as can be seen below in a tcpdump capture viewed in wireshark. We could easily create a signature for this ICMP traffic (and its operators could easily change it to look more like normal ICMP, which is why behavioral anomaly detection is often useful in combination with specification based intrusion detection): Immediately following the ICMP exchange, we can see the TCP/8822 traffic used by enye to deliver a rootshell:
Immediately following the ICMP exchange, we can see the TCP/8822 traffic used by enye to deliver a rootshell: This could also easily be blocked by a whitelisting firewall policy that allows inbound connections to legitimate web service and management ports. The resulting burst of firewall denies would tend to serve as a statistical detection method that something is amiss with the source VM.
This could also easily be blocked by a whitelisting firewall policy that allows inbound connections to legitimate web service and management ports. The resulting burst of firewall denies would tend to serve as a statistical detection method that something is amiss with the source VM.As in the physical world, there are performance and scalability considerations. A host running three dozen guests, each with a gigibit vNIC, could produce more traffic than a the local vIDS engine could process without dropped packets. For this reason, it is important to conserve cycles and limit IDS inspection to ports that are actually exposed. This does not concern me as much as some because we have very similar cost/scalability considerations in the physical world.
Extending full-packet intrusion detection coverage to cover core and distribution networks is rarely done in the physical world due to the prohibitive cost. Most of the time we have intrusion detection/prevention coverage at ingress and egress points and we monitor the core and distribution networks using some combination of netflow and firewall or access list events collected via syslog. There are numerous behavioral, statistical and specification based threat detects that can be produced using netflow and firewall events. Netflow analysis can produce a variety of useful detects. Methods include statistical (a traffic pattern is new, rare or changed by some number of standard deviations); behavioral (conversations with a netblock on a watchlist; traffic rate or duration indicates non-human source; traffic pattern is not a "known good" behavior for the source); geographic (e.g. conversation with a country on a watchlist or where no business relationship exists); geometric (traffic shape is abnormal for the expected protocol/port). If you have netflow data with content you can type applications and detect things like tunneling on ports 80/443 and and SSHing on random ports by spotting protocol/port mismatches.
This approach gives us broad visibility with acceptable cost in the physical world and I see no reason why the same strategy cannot be followed in the virtual world by collecting netflow and syslog telemetry from the virtual networks combined with judicious use of full-packet IDS inspection on live ports.
No comments:
Post a Comment