In modern cloud environments like AWS, we have a few options for doing network security monitoring and anomaly detection. We could use native OS-level firewall logs; we could layer on an instance based firewall product; or we could gather flow logs as long as our instances are running in a VPC. The disadvantage of all these approaches is that they are so-called "5-tuple" data types - limited to source and destination IP addresses, ports, and protocols. This is evident when we examine VPC flow logs which are similar to netflow:

Syscall data is superior as it is a 15-tuple data type with much richer data including key contextual parameters in addition to the traditional five tuples:
- The name and path of the process connected to the socket (e.g. which program or service engaged in the network activity)
- The commands and / or arguments associated with the process (e.g. what was the program trying to do)
- The user and group associated with the process (e.g. who did it)
- The PID and PPID of the process
With conventional flow or firewall logs, this kind of contextual detail often requires manual live response which is inherently unscalable due to its labor-intensive nature. Even where we have hunting teams available to do live response and chase down anomalous network activity, intermittent network activity tends to resist root causing unless an analyst happens to be doing live response when the activity manifests. Malware frameworks have long used intermittent and irregular command-and-control beaconing, for this reason, in order to resist detection and prolong persistence. In the cloud, we have another problem: servers may or may not live long enough for an analyst to perform live response. In semi- or hyper-ephemeral environments where instances are frequently created and destroyed, there may be simply be no instance to perform live response on by the time an alert rises to the top of the analysis queue, making effective threat hunting ineffective. In other cases, an instance may have been terminated by a developer or technician who thought this was the best course of action. In some environments, while servers persist long enough for live response, live response is infeasible when SSH or other command shells are unavailable due to philosophical design decisions that SSH or command shell accessibility is an anti-pattern.
The answer to all of this is to instrument in advance and gathering syscall data is the best way I've found in six years to do network security monitoring in the cloud. The Threat Stack technology is possibly the best way to gather and process syscall data at scale.. I've been doing active development in the tool for a while now and have arrived at a set of twenty rules that can detect any kind of network anomaly and produce actionable alerts. They're much more useful to most kinds of network alerts based on flow logs or firewall logs because I can do network behavior anomaly detection (NBAD) in fifteen dimensions instead of five. For example, consider these syscall logs on activity from an nmap scanner:
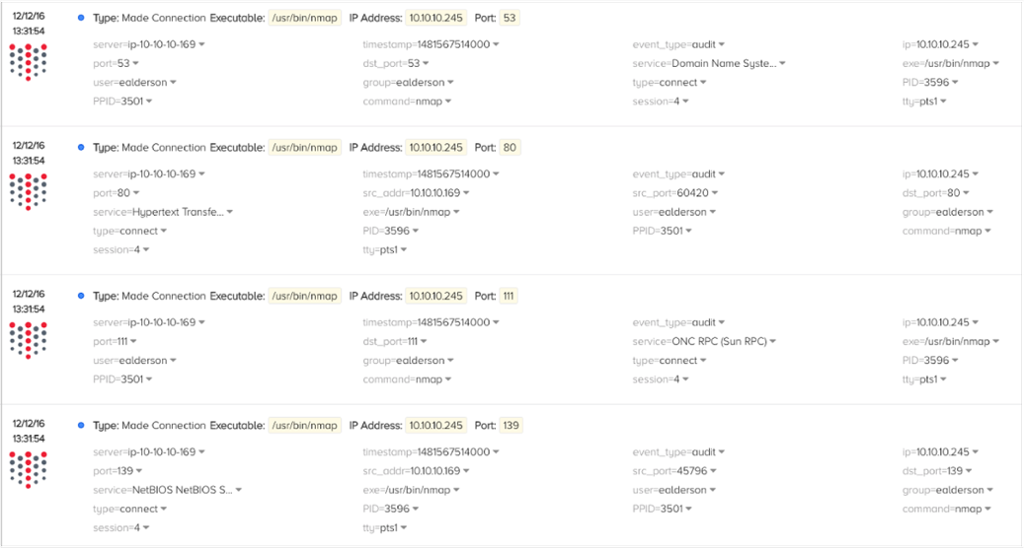
You can see all 15 tuples in the events which allow us to root cause this network behavior as an nmap scan in a matter of seconds without the need to get on the instance and perform live response in order to try and identify the process connected to the sockets, the user who invoked the process, the commands that were executed, and so on.
Using syscall data on file events, one can also perform complex and subtle anomaly detection on file and process events and I plan to explore this next. Example use cases include sensitive file access by shells or editors; file access by data exfil vectors like scp or ftp; and anomalous file access in general. Anomalous file access is another promising method for doing behavioral detection of exploit attempts; for example, a random process, like a Dirty Cow exploit, writing to /etc/passwd, or a non-mySQL process writing to a mySQL configuration file.
No comments:
Post a Comment